
2023年11月3日,北京大学国家发展研究院、北京大学数字金融研究中心在承泽园131教室举办了2023年秋季的第七场数字金融workshop。本期workshop由国发院助理教授、中心研究员胡佳胤主持,邀请到美国康奈尔大学管理学讲席教授、金融学终身教授丛林(Will Cong)进行了主题为《Building AI Models for Finance: Goal-Oriented Search(为金融领域构建人工智能模型:目标导向的搜寻)》的分享。五十余位老师和同学以线下或线上的方式参与了本次workshop,并与主讲嘉宾进行了深入的交流和讨论。



随着数字技术的兴起,人工智能(Artificial Intelligence, AI)在金融领域的应用是当下前沿的研究话题。丛林老师及其作者在2019年起就开始对该话题进行了一系列的研究和探索,在本次workshop中,丛林老师介绍了该领域的兴起背景和研究进展,并具体分享了自己和合作者进行的四项AI相关的最新研究。

第一项研究为《Goal-Oriented Portfolio Management Through Transformer-Based Reinforcement Learning(目标导向的投资组合管理:基于Transformer的强化学习)》。传统的资产组合管理范式存在着估计误差、资产定价和投资组合目标不一致、无行为-状态互动(Action-state Interaction)等缺陷。该研究探索了通过深度强化学习(Reinforcement Learning)直接优化投资组合管理目标的一种新的资产组合管理方式,作者将其命名为AlphaPortfolio。


作为金融领域第一个“大”模型,AlphaPortfolio包括三个部分, 用到超千万个参数。第一个部分使用SREMs(Sequence Representation Extraction Model,序列表征提取模型)从每个资产的历史状态中提取一个表征,第二个部分引入了CAAN(Cross-Asset Attention Network,跨资产注意力网络),将所有资产的表征作为输入端,提取资产之间的相关关系,得出胜算得分(Winner Score)。第三个部分生成投资组合,根据从CAAN中获得投资组合的胜算得分,得出最优投资组合权重。
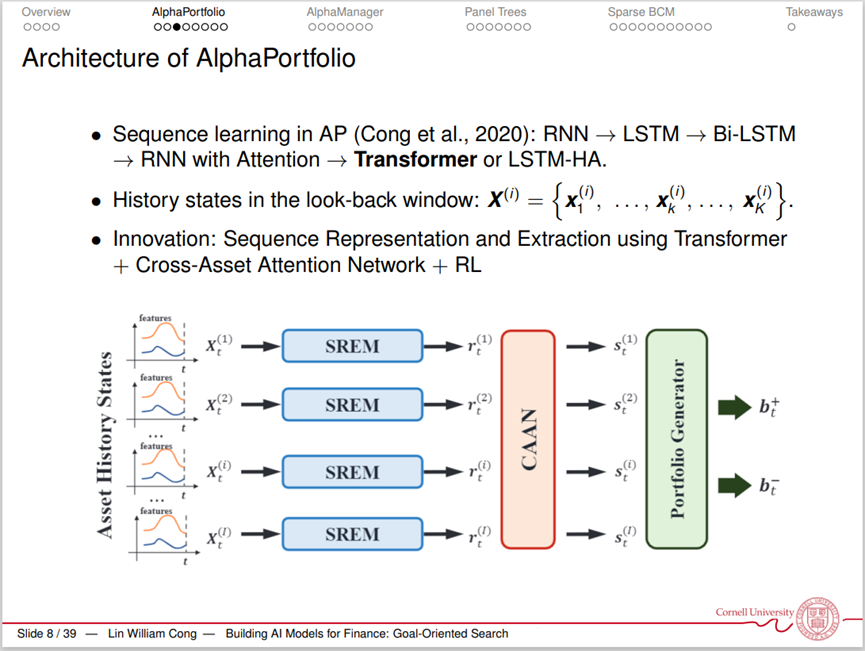
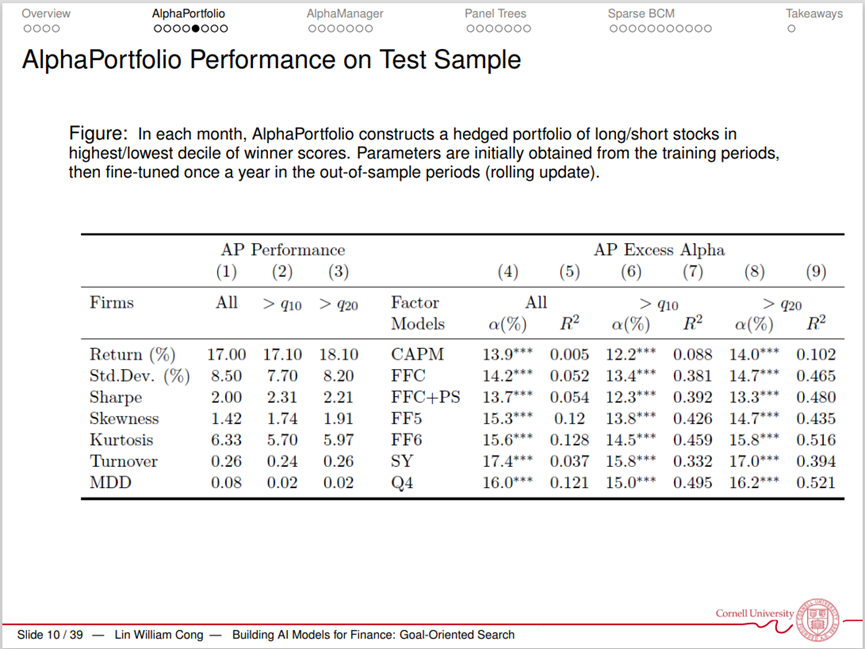
之后,作者将AlphaPortfolio应用于美国的股票。作者选择1965-1990年的美国股票数据来训练AlphaPortfolio模型,最优化目标为夏普比率(Sharpe Ratio),之后作者将训练后的模型应用于1990年之后的数据。结果发现,基于AlphaPortfolio模型的投资组合在收益率、波动率、夏普比率等方面都具有良好表现。

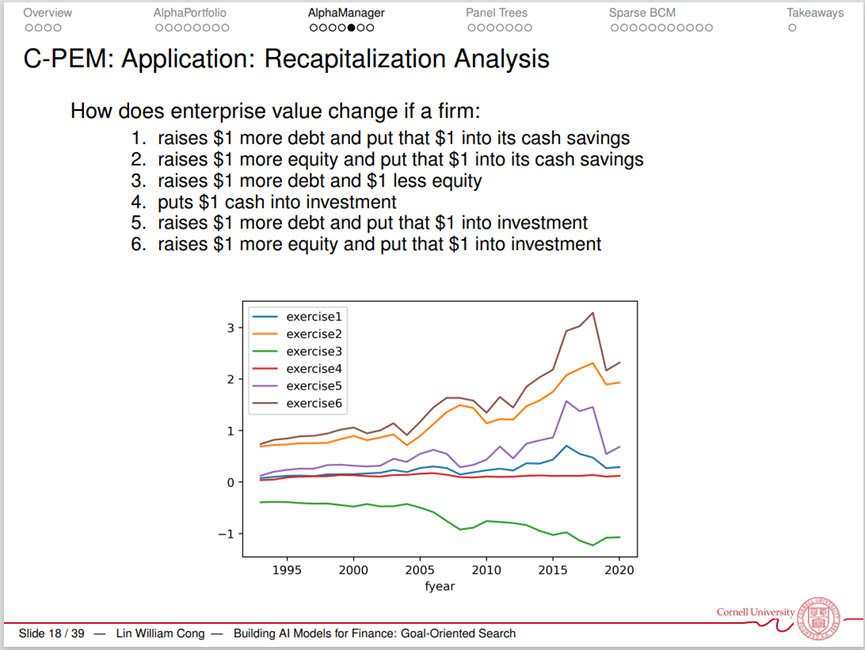
丛林老师分享的第二项研究为《A Data-Driven-Robust Control Approach to Corporate Finance and AI-Guided Managerial Actions(公司金融的数据驱动稳健控制方法和人工智能引领下的管理行为)》。简约式方法(Reduced Form)可以估计出公司金融问题中局部的因果关系,但往往缺乏对高维动态系统内现象的解释或预测,无法提供全方位决策的框架。结构估计(Structural Estimation)可以运用理论构造出反事实,但需要对所采用的理论施加一系列假设和限制。丛林老师及其合作者的研究将公司金融领域的问题理解为一系列随机控制问题(Stochastic Control Problem),并尝试构建基于数据的、不受理论模型可解性的反事实。


例如,作者选择了10个公司层面变量、4个市场行情变量、4个宏观变量作为状态变量(State Variable),基于这些状态变量和动态决策,公司可以选择不同的最优行为。之后,可以根据该模型预测公司在做出不同的行为决策后的公司价值(Enterprise Value)变化,从而帮助管理者进行决策。结合鲁棒控制的最新进展,此框架也可用来找到大数据大模型可解决问题的边界。
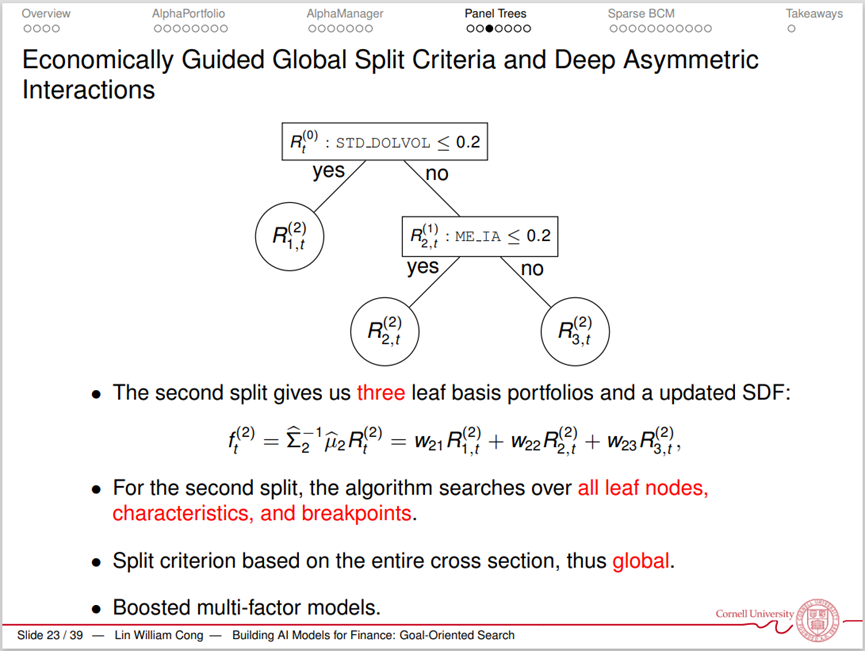
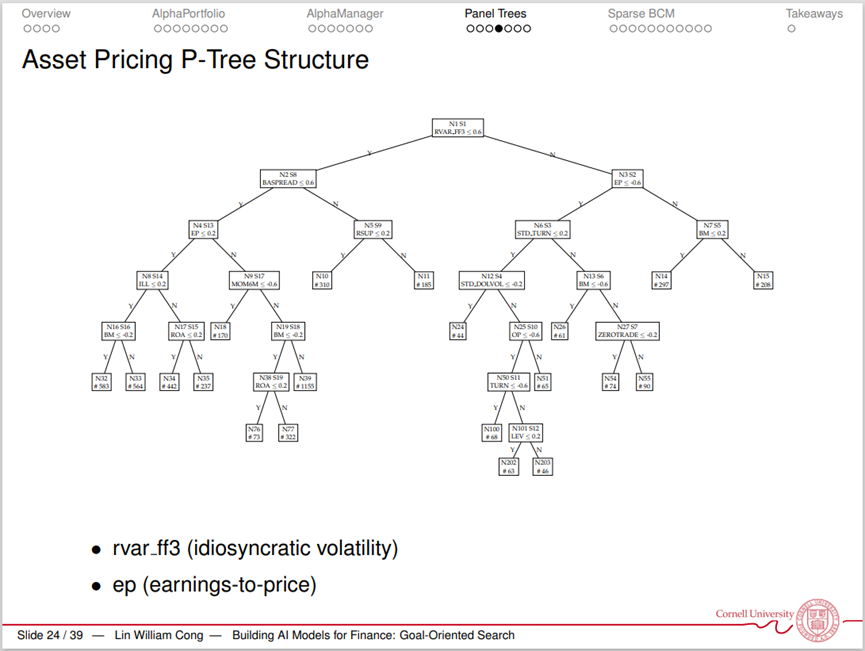
丛林老师分享的第三项研究为《Growing the Efficient Frontier on Panel Trees(在面板树上构造有效前沿)》。传统的决策树(Classification and Regression Tree, CART)具有定价核(Pricing Kernel)固定、递归(Recursion)未考虑经济因素、模型集成(Ensemble)可解释性差等缺陷。在该研究中,作者改进了决策树的拆分和选择方式,使其能系统性拓展资产分类(security sorting),生成测试资产组合,更加接近有效前沿(Efficient Frontier)。


在下图中,第二次分割后,算法会重新检索所有的叶子节点(Leaf Node),使最终产生的资产组合更靠近有效前沿。最终,这些多次拆分形成了面板树(P-Tree)。作者用美国资产数据对这一模型进行了检验,发现用P-Tree生成的资产组合相比其他模型下的资产组合具有更好的表现。
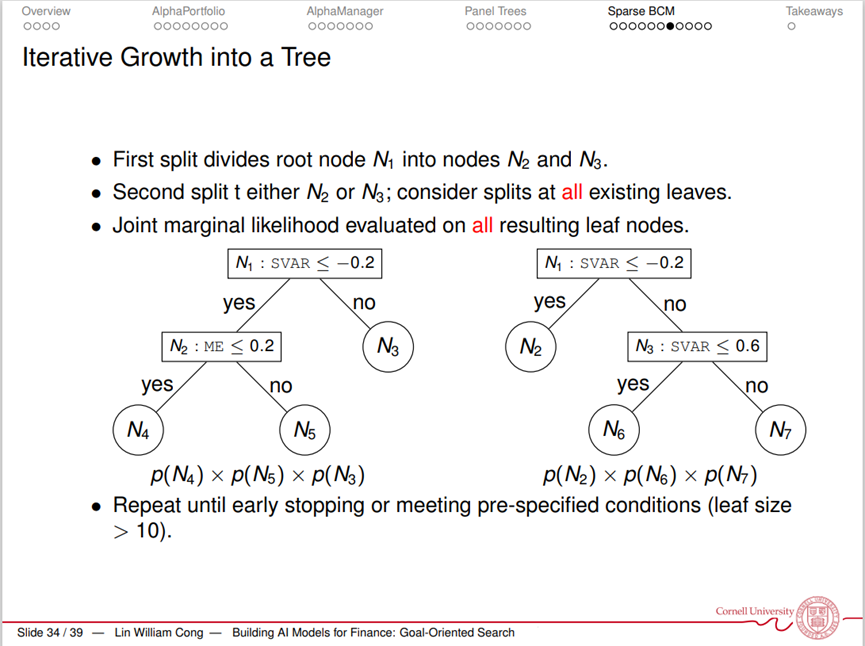
丛林老师分享的第四项研究为《Local Sparsity and Grouped Heterogeneity with an Application to Asset Pricing(局部稀疏性和分组异质性:资产定价应用)》。之前的资产定价模型往往只考虑了共同因素,而没有考虑针对于不同资产、不同环境下的异质性因素和异质性影响。本研究希望寻找一个模型,能够同时包括聚类观测(Observation Clustering)和异质性的模型选择(Heterogenous Model Selection)。

在研究中,作者使用尖峰-平板(Spike-and-Slab)先验的贝叶斯变量选择(Bayesian Variable Selection),并分离了估计和“树”的建立过程,在联合边际似然准则(Joint Marginal Likelihood Criterion)下同时集成模型和参数的不确定性。此架构也适用于广泛的有群异质性 (Grouped Heterogeneity) 的面板数据分析。

最后,丛林老师总结了人工智能和机器学习(Machine Learning, ML)在金融中主要的运用领域和可行方向。

北京大学国家发展研究院副院长、数字金融研究中心主任黄益平,北京大学数字金融研究中心特约高级研究员、对外经济贸易大学金融学院副院长张海洋,北京大学国家发展研究院助理教授胡佳胤,北京大学国家发展研究院助理教授李明浩,北京大学国家发展研究院助理教授彭聪,北京大学习近平新时代中国特色社会主义思想研究院助理教授陈佳,北京大学数字金融研究中心特约研究员、中央财经大学金融学院讲师王靖一,北京外国语大学国际商学院讲师穆远东在报告过程中提问并与丛林教授进行了深入讨论。
丛林老师是和康奈尔大学金融科技计划(the FinTech at Cornell Initiative)及数字经济与金融科技实验室(The Digital Economics and Financial Technology (DEFT) Lab)的创始人。DEFT由瑞波大学区块链研究计划(Ripple University Blockchain Research Initiative, URBI)等机构资助。DEFT致力于探索金融科技、数字化和人工智能的最新进展,尤其关注其在金融领域的应用。在丛林老师的引领下,DEFT展开了各类前沿的学术研究,并和康纳尔大学以及其他学校研究人员积极合作,共同探索金融和数字技术相结合的未来潜力。(DEFT LAB | Lin William Cong)