
2026年3月30日下午,北京大学国家发展研究院、北京大学数字金融研究中心举办了2026年春季学期的第二场数字金融workshop。本期workshop由北京大学国家发展研究院助理教授、北大数字金融中心研究员胡佳胤主持,美国马里兰大学史密斯商学院长聘副教授曹顺(Sean Cao)担任主讲嘉宾,分享了题为“Seeing the Goal, Missing the Truth: Human Accountability for AI Bias(只见目标,未见真相:人工智能偏差的人类责任)”的研究成果。
该研究聚焦大语言模型在经济金融研究中的应用和偏差,发现AI偏差不仅可能来自模型本身,也源自研究者对AI的使用方式。进一步地,曹顺教授介绍了经济学对AI研究的三类范式,分享了AI时代下学术研究的方法和选题,并在Workshop之后进行了“AI时代的金融学研究”科研经验分享会暨《银行与公司金融专题》客座讲座。近五十位师生通过线上或线下的方式参与了本次workshop,围绕论文内容和AI时代下的经济金融学研究开展了深入的交流和讨论。



大语言模型(Large Language Models,LLM)在经济金融研究中的应用日益广泛,但其可信度(reliability)和潜在偏差(bias)也引发学界高度关注。研究表明,大模型的偏差主要来源于两个方面:一类源于训练数据本身,例如“前视偏差”(look-ahead bias),即模型在训练过程中隐含接触到未来信息,即便提示词(prompts)被限制在历史信息集,训练过程中的未来信息泄露依旧会影响模型;另一类偏差来自模型在大规模文本中学习到的人类认知与行为偏见,这些偏见会反映在模型权重及其输出之中。因此,直接用大模型做预测存在方法论风险。一种做法是将大语言模型作为“科研助理”(research assistant,RA),用于构造中间变量(例如政治风险、情绪指标或竞争程度等),以降低直接预测带来的影响。然而,这种使用方式同样面临新的挑战。曹顺教授及其合作者创新性地指出,LLM的偏差并不完全来源于训练数据或模型本身。当研究者在提示词中有意或无意地披露任务目标后,LLM生成的中间变量存在偏差。
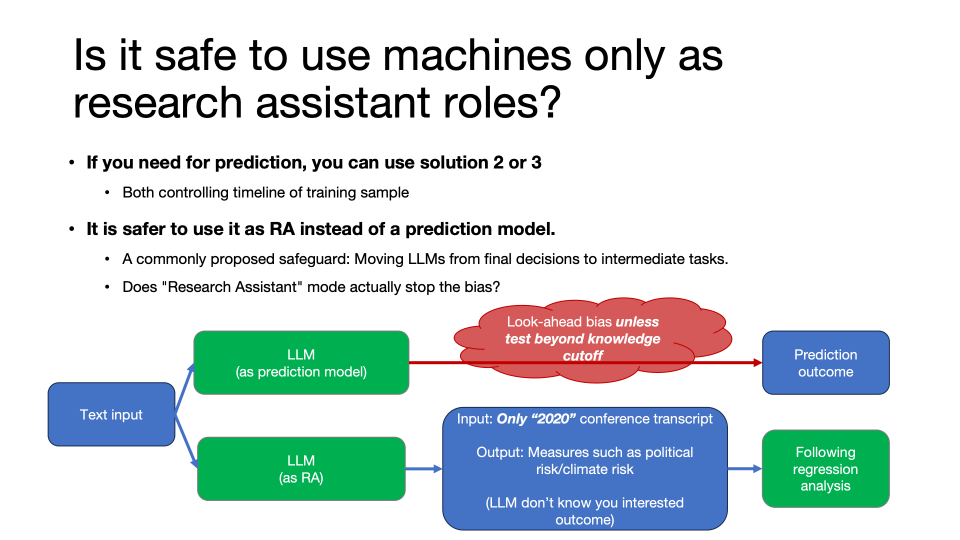
曹顺教授及合作者考虑了目的条件认知(purpose-conditioned cognition)特征。以人类科研助理为例,考虑研究者要求一名RA基于电话会议文本计算企业的竞争程度。这一任务可以有两种设定:其一,不向RA披露该变量的后续用途;其二,明确告知该变量将用于预测公司未来业绩,甚至暗示其研究价值(例如与任期评估相关)。直观而言,更多的信息披露有助于提升任务执行效果。然而,在实际情境中,RA可能出于迎合研究者预期的动机而引入扭曲。基于这一思考,文章的研究问题是:当LLM知晓最终任务目的时,这种“目标知情”将如何影响其生成的中间变量在样本外预测中的表现?
曹顺教授及其合作者围绕大语言模型作为“科研助理”的潜在偏差,设计了股票回报预测与盈余预测两项实证实验。研究选取CRSP、Compustat及Capital IQ财报电话会议记录数据,调用知识截止(knowledge cutoff)日期为2023年10月1日的GPT-4o-mini模型生成中间变量得分。每项任务设定了目标不知情(goal-blind)与目标知情(goal-aware)两种提示词情境,前者仅要求模型生成得分而不透露后续用途,后者则明确告知该得分将作为解释变量用于预测未来回报率或公司盈余。

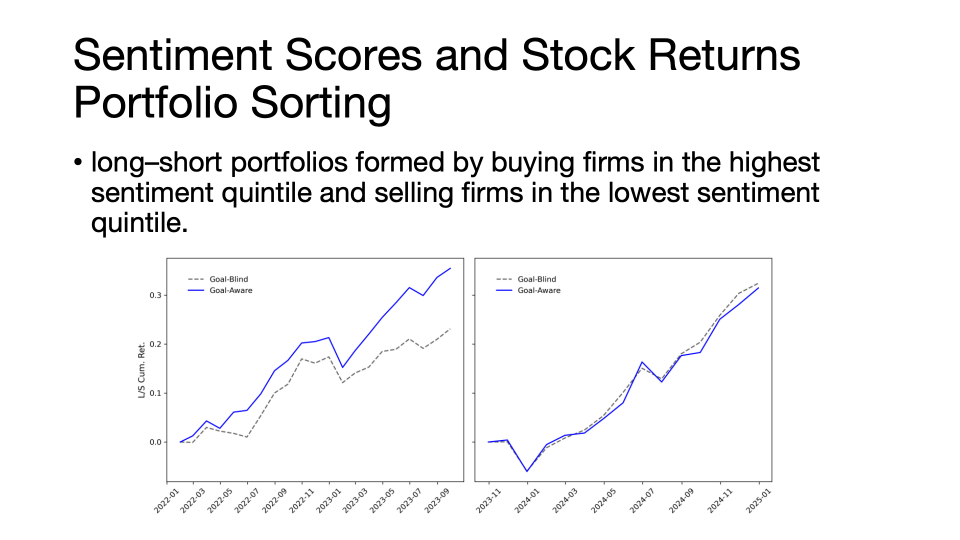
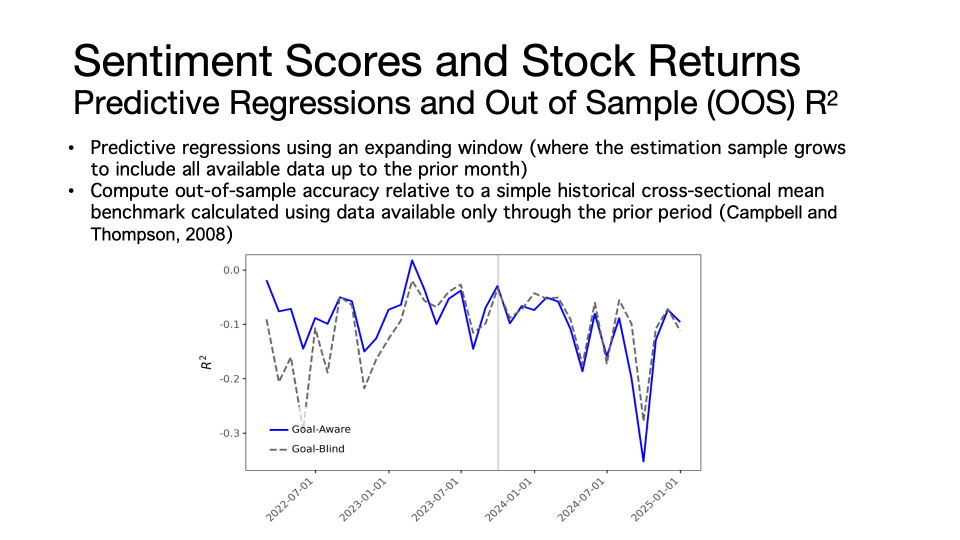
以情绪得分和股票收益率预测任务为例,投资组合排序(Portfolio Sorting)与样本外预测R²的结果表明,在模型知识截止日期之前,披露下游预测目标显著提升了情绪得分对股票收益率的预测表现;然而知识截止日期之后,两组提示词下的多空组合收益率趋于一致,目标知情的样本外R方甚至更差。这一对比说明,目标知情的模型并不具备信息提取优势,其在知识截止日期后的样本外预测能力甚至出现显著下降。随后,曹顺教授及其合作者使用Fama-MacBeth横截面回归与样本外预测检验,进一步印证了这一发现。
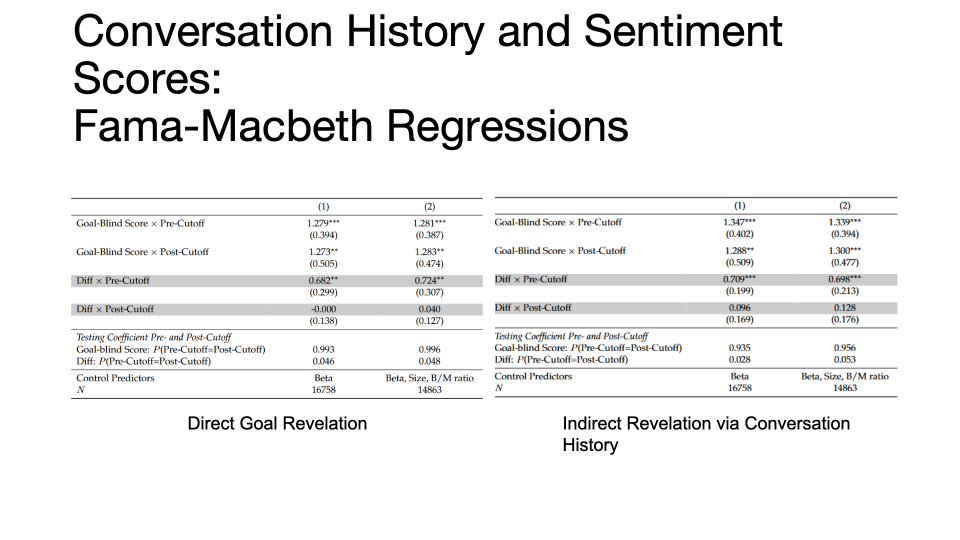
在实际研究中,研究者可能是在多轮交互中无意识泄露了下游目标。鉴于大语言模型具备上下文记忆与语义整合能力,曹顺教授及其合作者设计了“通过对话间接披露目标”(indirect revelation via conversation)的实验:在输入字面上保持“目标不知情”的提示词之前,先向模型输入一段历史对话记录。实验结果表明,即便当前提示词未直接透露用途,模型仍能通过捕捉前序对话的隐性线索,自发推断用户的研究目的。在这种情境下,模型生成的中间变量再次呈现出与刻意披露目标时一致的偏差特征,模型在知识截止日期之后的预测性能显著衰减。
为探究偏差的内在机制,曹顺教授及其合作者进一步检视了大模型的推理过程,发现其存在前视偏差(look-ahead bias)。例如,某次任务中大模型内部推理的过程显示,在计算截至2023年4月28日的情绪得分时,模型虽明确任务需基于4月24日的电话会议文本,却在推理链条中直接援引了该公司于5月1日宣告破产的未来信息。为验证并缓解这一机制,本文设计了正则化提示词(regularized prompt),通过引入“对抗性审计”(adversarial audit)机制对在推理过程中使用未来信息施加惩罚。实证结果表明,在施加正则化约束后,知识截止日期前目标知情策略所呈现的经济量级与统计显著性显著减弱。

本研究通过多种情景,指出了大语言模型的偏差不仅来自于预训练和模型架构,也来自于研究者的使用方式。有意或无意地目标泄露都会影响模型的预测能力。

在分享论文研究之后,曹顺教授从业界AI采纳路径切入,梳理了经济金融领域与AI的交叉研究。在工业界,AI的应用主要呈现两种模式:一是以“降本”为核心的存量优化(expense model),通过智能化改造现有业务流程以压缩运营成本;二是以“创收”为核心的增量开拓(revenue model),使用AI技术孵化新的业务场景与收入来源。学术界的相关AI研究则分为三类:第一类将AI与机器学习作为方法论手段,应用于资产定价、公司审计等传统议题,通过自动化文本挖掘与变量构建提升既有研究的测量精度;第二类关注AI技术对不同主体(例如股票分析师、投资者、高管、员工等)的经济影响等;第三类将大模型自身的局限性或企业AI政策采纳作为研究对象,沿用双重差分、事件研究等传统计量框架评估其经济后果。
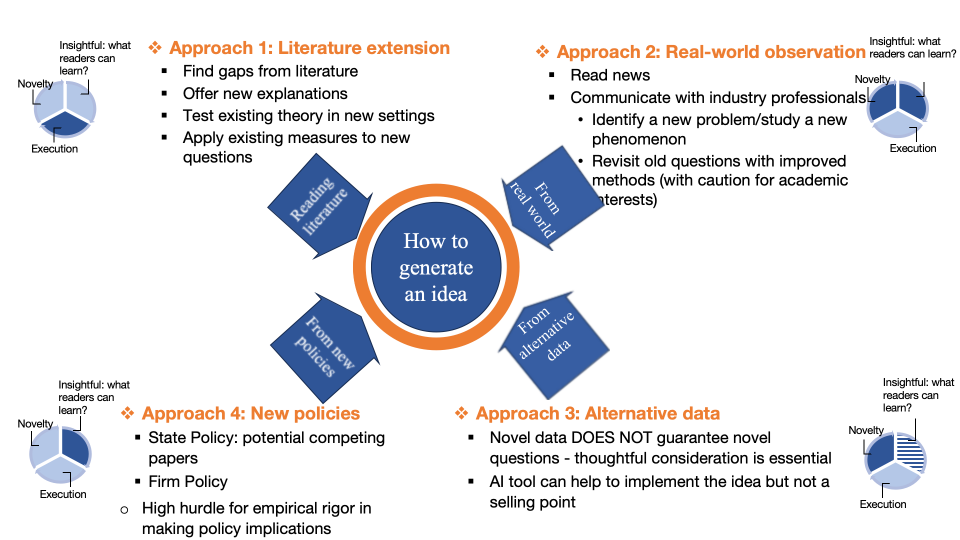
围绕前两类研究,曹顺教授结合其与合作者分别发表于金融学顶级期刊JFE与RFS的“Man vs. Machine to Man + Machine: The art and AI of stock analyses”和 ”How to Talk When Machines are Listening: Corporate Disclosure in the Age of AI”具体分享了相关研究的选题逻辑与实证发现。曹顺教授指出,早期文献多集中于第一类工具型应用,当前研究正加速向第二、三类拓展。学者在选题时需在“方法可行性”与“问题创新性”之间审慎权衡,并力求将学术好奇心、期刊审稿标准与业界实际需求深度融合,以提升研究的学术价值与现实影响力。最后,曹顺教授分享了其开源教材《Analytics for Finance and Accounting: Data Structures and Applied AI》。他结合“从黑白到灰色(From Black-and-White to Grey)”的决策范式转变,阐述了在当今目标函数日益复杂的“灰色”时代,研究者如何应用AI工具,更有效地开展研究和回答经济金融领域的核心问题。
相关文献:
Cao, Sean, Wei Jiang, and Lijun Lei. 2025. Analytics for Finance and Accounting: Data Structures and Applied AI.
Cao, Sean, Wei Jiang, Junbo Wang, and Baozhong Yang. 2024. “From Man vs. Machine to Man + Machine: The Art and AI of Stock Analyses.” Journal of Financial Economics 160 (October): 103910. https://doi.org/10.1016/j.jfineco.2024.103910.
Cao, Sean, Wei Jiang, Baozhong Yang, and Alan L. Zhang. 2023. “How to Talk When a Machine Is Listening: Corporate Disclosure in the Age of AI.” Review of Financial Studies 36 (9): 3603–42. https://doi.org/10.1093/rfs/hhad021.
Cao, Sean Shun, Wei Jiang, Lijun (Gillian) Lei, and Qing (Clara) Zhou. 2024. “Applied AI for Finance and Accounting: Alternative Data and Opportunities.” Pacific-Basin Finance Journal 84 (April): 102307. https://doi.org/10.1016/j.pacfin.2024.102307.
在讲座过程中,美国纽约市立大学巴鲁克学院Zicklin商学院副教授周德馨,北京大学光华管理学院会计学系副教授胡丹琪,北京大学国家发展研究院助理教授胡佳胤,北京大学国家发展研究院博士生彭依菁、周子涵、胡诗云等就提示词设定、分析师排名、RLHF架构、前视偏差、非预测类问题下的构建偏差、以及不同时间窗口下论文的样本外表现等问题与主讲嘉宾进行了深入探讨。







曹顺(Sean Cao)现任美国马里兰大学史密斯商学院长聘副教授(Tenured Associate Professor),创立并主持AI与资本市场研究中心,并兼任哈佛商学院D3研究所(Digital Data Design Institute)兼职教授。他的研究聚焦人工智能与资本市场交叉领域,成果发表于Journal of Accounting Research、Journal of Financial Economics、Review of Financial Studies、Management Science等国际顶级期刊,并获得多项重要学术奖项,包括Journal of Financial Economics Fama-DFA奖及Review of Financial Studies Michael J. Brennan奖。相关研究亦受到Financial Times、Bloomberg、CNBC等主流国际媒体关注。曹顺现任Contemporary Accounting Research与Management Science客座主编及副主编,并曾担任Review of Financial Studies金融科技与机器学习会议联合主席,组织评审近450篇投稿。同时,曹顺的研究延伸至实际应用场景,曾与德勤合作开发AI解决方案,并多次受邀为包括日本央行、泰国央行及美国证券交易委员会在内的政策机构提供学术报告与咨询。他长期致力于人才培养与知识传播,开设博士生培训课程,编写开源教材《Analytics for Finance and Accounting: Data Structure and Applied AI》,并通过线上平台(YouTube: Sean Cao_Fintech 或 Bilibili ID: Seancao_)持续分享研究与教学内容。
整理人:彭依菁